
Humans have a remarkable sensitivity to motion, which is one of the most obvious visual clues in the natural world. The complexity of measuring and capturing physical features on a wide scale makes it difficult to train a model to understand genuine scene motion, yet humans can perceive motion with ease. This also pertains to the dynamics within the AI domain, where the need for VR Industrial Training by Twin Reality is essential to fully grasp and value any motion within the 3D environment.
Fortunately, recent advances in generative models, notably conditional diffusion models, have ushered in a new era of modelling highly detailed and diverse distributions of real images based on text input. Recent studies also suggest that there is tremendous potential for applications by extending this modelling to other domains, such as movies and 3D geometry.
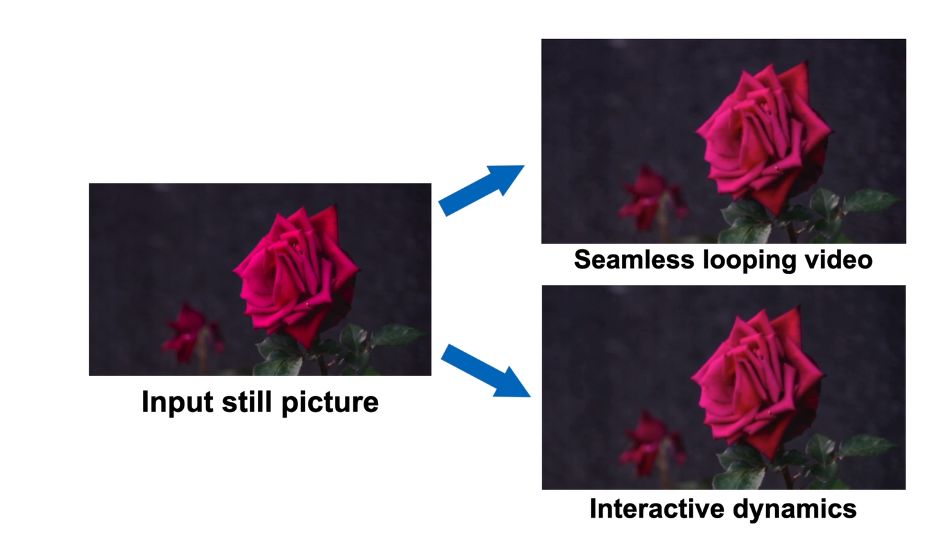
What is Generative Image Dynamics?
The Google research team offers a revolutionary technique called Generative Image Dynamics to produce photo-realistic animations built from a single image, significantly outperforming the efficiency of earlier techniques. It also opens the door to a variety of other uses, like the development of interactive animations.
With the ability to create photo-realistic animations from a single static image while greatly outperforming earlier baseline techniques, Generative Image Dynamics represents a very promising advancement.
As we continue to witness the evolution of generative image dynamics, the Google Research Team remains at the forefront, shaping the future of visual computing and image generation.

